5.3. Example 2 - SXD+111 Point Source - Using the “Reduce” class API
In this example, we will reduce the GNIRS crossed-dispersed observation of an erupting recurrent nova using the DRAGONS API.
This cross-dispersed observation uses the 111 l/mm grating, the short-blue camera and the 0.3 arcsec slit. The dither pattern is the standard ABBA, one set for each of the three central wavelength settings. The results from the three wavelength settings will be stitched together at the end.
5.3.1. The dataset
If you have not already, download and unpack the tutorial’s data package. Refer to Downloading tutorial datasets for the links and simple instructions.
The dataset specific to this example is described in:
Here is a copy of the table for quick reference.
Science |
N20191013S0006-09 (1.55
 m) m)N20191013S0010-13 (1.68
m)N20191013S0014-17 (1.81
m) |
Science flats |
N20191013S0036-51 (1.55
m)N20191013S0054-69 (1.68
m)N20191013S0072-87 (1.81
m) |
Pinholes |
None available
|
Science arcs |
N20191013S0034-35 (1.55
m)N20191013S0052-53 (1.68
m)N20191013S0070-71 (1.81
m) |
Telluric |
N20191013S0022-25 (1.55
m)N20191013S0026-29 (1.68
m)N20191013S0030-33 (1.81
m) |
BPM |
bpm_20121101_gnirs_gnirsn_11_full_1amp.fits
|
5.3.2. Setting up
First navigate to your work directory in the unpacked data package.
cd <path>/gnirsxd_tutorial/playground
The first steps are to import libraries, set up the calibration manager, and set the logger.
5.3.2.1. Configuring the interactive interface
In ~/.dragons/, add the following to the configuration file dragonsrc:
[interactive]
browser = your_preferred_browser
The [interactive] section defines your preferred browser. DRAGONS will open
the interactive tools using that browser. The allowed strings are “safari”,
“chrome”, and “firefox”.
5.3.2.2. Importing libraries
1import glob
2
3import astrodata
4import gemini_instruments
5from recipe_system.reduction.coreReduce import Reduce
6from gempy.adlibrary import dataselect
The dataselect module will be used to create file lists for the
biases, the flats, the arcs, the telluric star, and the science observations.
The Reduce class is used to set up and run the data
reduction.
5.3.2.3. Setting up the logger
We recommend using the DRAGONS logger. (See also Double messaging issue.)
7from gempy.utils import logutils
8logutils.config(file_name='gnirsls_tutorial.log')
5.3.2.4. Set up the Local Calibration Manager
Important
Remember to set up the calibration service.
Instructions to configure and use the calibration service are found in Setting up the Calibration Service, specifically the these sections: The Configuration File and Usage from the API.
We recommend that you clean up your working directory (playground) and
create a fresh calibration database (caldb.init(wipe=True)) when you
start a new example.
5.3.3. Create file lists
This data set contains science and calibration frames. For some programs, it could contain different observed targets and different exposure times depending on how you like to organize your raw data.
The DRAGONS data reduction pipeline does not organize the data for you. You have to do it. However, DRAGONS provides tools to help you with that.
The first step is to create input file lists. The tool “dataselect” helps. It uses Astrodata tags and descriptors to select the files and send the filenames to a text file that can then be fed to “Reduce”. (See the Astrodata User Manual for information about Astrodata and for a list of descriptors.)
The first step is to create input file lists. The tool “dataselect” helps.
It uses Astrodata tags and descriptors to select the files and
send the filenames to a text file that can then be fed to Reduce. (See the
Astrodata User Manual for information about Astrodata and for a list
of descriptors.)
The first list we create is a list of all the files in the playdata
directory.
9all_files = glob.glob('../playdata/example2/*.fits')
10all_files.sort()
We will search that list for files with specific characteristics. We use
the all_files list as an input to the function
dataselect.select_data() . The function’s signature is:
select_data(inputs, tags=[], xtags=[], expression='True')
We show several usage examples below.
5.3.3.1. Three lists for the flats
The GNIRS XD flats are obtained using two different lamps to ensure that each order is illuminated at a sufficient level. The software will stack each set and automatically assemble the orders into a new flat with all orders well illuminated.
The particularily of this dataset is that there are three central wavelength settings that each need to be reduced separately.
You will use “dataselect” to select each set of flats associated with the configurations used for the science observations.
But first, to see which central wavelengths have been used, run showd on the flats.
11for filename in dataselect.select_data(all_files, ['FLAT']):
12 ad = astrodata.open(filename)
13 print(filename, ad.central_wavelength())
../playdata/example2/N20191013S0036.fits 1.55e-06
../playdata/example2/N20191013S0037.fits 1.55e-06
...
../playdata/example2/N20191013S0054.fits 1.68e-06
../playdata/example2/N20191013S0055.fits 1.68e-06
...
../playdata/example2/N20191013S0072.fits 1.81e-06
../playdata/example2/N20191013S0073.fits 1.81e-06
14flats155 = dataselect.select_data(all_files, ['FLAT'], [],
15 dataselect.expr_parser('central_wavelength==1.55e-6'))
16flats168 = dataselect.select_data(all_files, ['FLAT'], [],
17 dataselect.expr_parser('central_wavelength==1.68e-6'))
18flats181 = dataselect.select_data(all_files, ['FLAT'], [],
19 dataselect.expr_parser('central_wavelength==1.81e-6'))
Note that we have downloaded only the October data from that program. If the September data were also in our raw data directory, we would have to add a date constraint to the expression, like this:
flats155Oct = dataselect.select_data(all_files, ['FLAT'], [],
dataselect.expr_parser('central_wavelength==1.55e-6 and ut_date=="2019-10-13"'))
5.3.3.2. A list for the pinholes
This program does not use a pinholes observation.
The orders in the cross-dispersed raw data are significantly slanted and curved on the detector. A pinhole would trace that curvature.
However, the edges of the orders in the processed flat can be used to determine the position of each order, the pinholes observations simply lead to a more accurate model of the order positions and of the spatial distortion component.
We do not have pinholes, therefore all steps related to pinholes, their creation and their usage will be skipped in this tutorial.
If you had pinholes, you would select them like for the flats above using “PINHOLE” instead of “FLAT”.
5.3.3.3. Three lists for the arcs
The GNIRS cross-dispersed arcs were obtained between the telluric and the science observation. Often two are taken for each configuration. If we decide to use both, they will be stacked.
Here, like for the flats, we need to create a list for each of the three configurations.
20arcs155 = dataselect.select_data(all_files, ['ARC'], [],
21 dataselect.expr_parser('central_wavelength==1.55e-6'))
22arcs168 = dataselect.select_data(all_files, ['ARC'], [],
23 dataselect.expr_parser('central_wavelength==1.68e-6'))
24arcs181 = dataselect.select_data(all_files, ['ARC'], [],
25 dataselect.expr_parser('central_wavelength==1.81e-6'))
5.3.3.4. Three lists for the telluric
DRAGONS does not recognize the telluric star as such. This is because, at
Gemini, the observations are taken like science data and the GNIRS headers do not
explicitly state that the observation is a telluric standard. In most cases,
the observation_class descriptor can be used to differentiate the telluric
from the science observations, along with the rejection of the CAL tag to
reject flats and arcs. Telluric stars will be observed under the partnerCal
or progCal classes, the science observation under the science class.
26tellurics155 = dataselect.select_data(
27 all_files,
28 [],
29 ['CAL'],
30 dataselect.expr_parser('observation_class!="science" and central_wavelength==1.55e-6')
31)
32tellurics168 = dataselect.select_data(
33 all_files,
34 [],
35 ['CAL'],
36 dataselect.expr_parser('observation_class!="science" and central_wavelength==1.68e-6')
37)
38tellurics181 = dataselect.select_data(
39 all_files,
40 [],
41 ['CAL'],
42 dataselect.expr_parser('observation_class!="science" and central_wavelength==1.81e-6')
43)
5.3.3.5. A list for the science observations
The science observations can be selected from the “observation class”
science. This is how they are differentiated from the telluric
standards which are set to partnerCal or progCal.
We already know that we have multiple central_wavelength settings and that we will need a list of each.
If we had multiple targets, we would need to split them into separate lists
using the object descriptor. Here we only have one target.
44science155 = dataselect.select_data(
45 all_files,
46 [],
47 ['CAL'],
48 dataselect.expr_parser('observation_class=="science" and central_wavelength==1.55e-6')
49)
50science168 = dataselect.select_data(
51 all_files,
52 [],
53 ['CAL'],
54 dataselect.expr_parser('observation_class=="science" and central_wavelength==1.68e-6')
55)
56science181 = dataselect.select_data(
57 all_files,
58 [],
59 ['CAL'],
60 dataselect.expr_parser('observation_class=="science" and central_wavelength==1.81e-6')
61)
5.3.4. Bad Pixel Mask
The bad pixel masks (BPMs) are handled as calibrations. They are downloadable from the archive instead of being packaged with the software. They are automatically associated like any other calibrations. This means that the user now must download the BPMs along with the other calibrations and add the BPMs to the local calibration manager.
See Get the BPMs in Tips and Tricks to learn about the various ways to get the BPMs from the archive.
To add the static BPM included in the data package to the local calibration database:
62for bpm in dataselect.select_data(all_files, ['BPM']):
63 caldb.add_cal(bpm)
5.3.5. Master Flat Field
GNIRS XD flat fields are normally obtained at night along with the
observation sequence to match the telescope and instrument flexure. The
processed flat is constructed from two sets of stacked lamp-on flats, each
exposed differently to ensure that all orders in the reassembled flat are
well illuminated. You do not have to worry about the details, as long as you
pass the two sets of raw flats as input to the Reduce instance, the software
will take care of the assembly.
The processed flat will also contain the illumination mask that identify the location of the illuminated areas in the array, ie, where the orders are located. By tracing the edges of the illuminated areas, a rectification model is also calculated.
Each central wavelength settings must be reduced separately.
64reduce_flats155 = Reduce()
65reduce_flats155.files.extend(flats155)
66reduce_flats155.runr()
67
68reduce_flats168 = Reduce()
69reduce_flats168.files.extend(flats168)
70reduce_flats168.runr()
71
72reduce_flats181 = Reduce()
73reduce_flats181.files.extend(flats181)
74reduce_flats181.runr()
It might be useful to run the flat reduction in interactive mode. Also, in
this case, using ('normalizeFlat:grow', 2) helps rejecting the pixels near
the edge and ensure a smoother fit. You can play with the other parameters
too.
75reduce_flats155 = Reduce()
76reduce_flats155.files.extend(flats155)
77reduce_flats155.uparms = dict([
78 ('normalizeFlat:grow', 2),
79 ('interactive', True),
80 ])
81reduce_flats155.runr()
82
83reduce_flats168 = Reduce()
84reduce_flats168.files.extend(flats168)
85reduce_flats168.uparms = dict([
86 ('normalizeFlat:grow', 2),
87 ('interactive', True),
88 ])
89reduce_flats168.runr()
90
91reduce_flats181 = Reduce()
92reduce_flats181.files.extend(flats181)
93reduce_flats181.uparms = dict([
94 ('normalizeFlat:grow', 2),
95 ('normalizeFlat:niter', 2),
96 ('interactive', True),
97 ])
98reduce_flats181.runr()
The interactive tools are introduced in section Interactive tools.
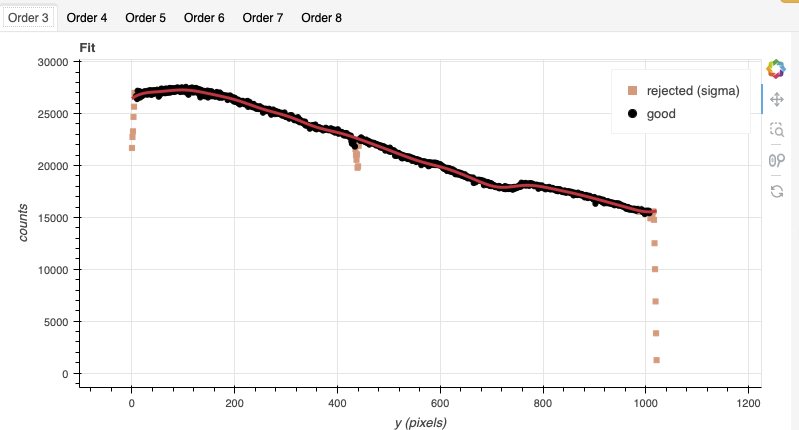
Note
In some data the “odd-even effect”, some noise pattern affecting odd and even rows differently cannot not be perfectly corrected. In those cases, you will see the black dots define two separated signal trace. Get the fit to trace the middle. In most cases, the effect in science and telluric data is removed during the flat fielding.
5.3.6. Processed Pinholes - Rectification
The pinholes are used to determine the rectification of the slanted and curved orders.
This program does not have pinholes associated with it. It is okay, the edges of the orders have been traced when the flats were reduced. This can be used for the rectification. The spatial axis is not as well sampled but depending on the science using just the edges from the flat can be sufficient.
Since the attachPinholeRectification step will have to be skipped for
all the recipes that requests it, let’s save ourselves some typing and let’s
put that instructions dictionary that we can attach later to our Reduce
instance.
99nopinhole = dict([('attachPinholeRectification:skip_primitive', True)])
If you had pinhole observation, just like the flats they would need to be reduced each configuration separately.
5.3.7. Wavelength Solution
Obtaining the wavelength solution for GNIRS cross-dispersed data can be a complicated topic. The quality of the results and whether to use arc lamp or sky lines depends greatly on the wavelength regime and the grating.
Caution
Do pay great attention to the wavelength calibration. It is critical to the telluric modelling. It can be particularly challenging with the 111 l/mm grating given the limited wavelength range each order covers.
Our configurations in this example is cross-dispersed with short-blue camera, the SXD prism, and the 111 l/mm grating. With this grating, each order covers only a short wavelength range. Some orders will not contain a sufficient number of lines from the arc lamp. In some cases, we will have to use the sky emission lines, or even the telluric absorption features to get an accurate enough wavelength solution for an order.
Note
The current software calculates a wavelength solution for each order separately. A “2D solution” that would use all the lines from all the orders together is not yet available.
5.3.7.1. Summary of the Technique for Science Quality
The wavelength calibration is critical to the telluric modelling. In fact, the
best way to know which wavelength solutions work for each order and which ones
do not is to run fitTelluric interactively and see if the modeling works
well or not.
For quicklook results, you might not care to go through the trouble, but for a science quality product, you will have to go through the following steps.
For each central wavelength setting:
Produce a wavelength solution from the arc lamp.
Produce a wavelength solution from the sky emission lines in the science data.
Launch the telluric star reduction in interactive mode.
First using the arc lamp solution. Inspect each order. Identify which one works, which one does not.
Then using the sky lines solution. Inspect each order. Identify which one works, which one does not.
Piece together the best solutions for each order and add this “processed arc” to the calibration database.
Clean up the calibration database of the arc and sky lines solutions, leaving only the ones built during Step 4.
Later, you will be doing the “official” reduction of the telluric star and the reduction of the science target using the wavelength solution put together in step 4. It will be picked up automatically.
Hint
It is expected that for a set of H-band central wavelengths, like this case, sky emission lines will provide the most comprehensive coverage. It is not complete however and it will need to be complemented with arc lamp solutions.
5.3.7.2. Solution from the Arc Lamp
During the processing of the arc, the illumination mask and the rectification model will be obtained from the processed flat.
100reduce_arcs155 = Reduce()
101reduce_arcs155.files.extend(arcs155)
102reduce_arcs155.uparms = dict([
103 ('interactive', True),
104 ]) | nopinhole
105reduce_arcs155.runr()
106
107reduce_arcs168 = Reduce()
108reduce_arcs168.files.extend(arcs168)
109reduce_arcs168.uparms = dict([
110 ('interactive', True),
111 ]) | nopinhole
112reduce_arcs168.runr()
113
114reduce_arcs181 = Reduce()
115reduce_arcs181.files.extend(arcs181)
116reduce_arcs181.uparms = dict([
117 ('interactive', True),
118 ]) | nopinhole
119reduce_arcs181.runr()
The interactive tools are introduced in section Interactive tools.
Each order can be inspected individually by selecting the tabs above the plot.
The general shape of the fit for each order should look like this:
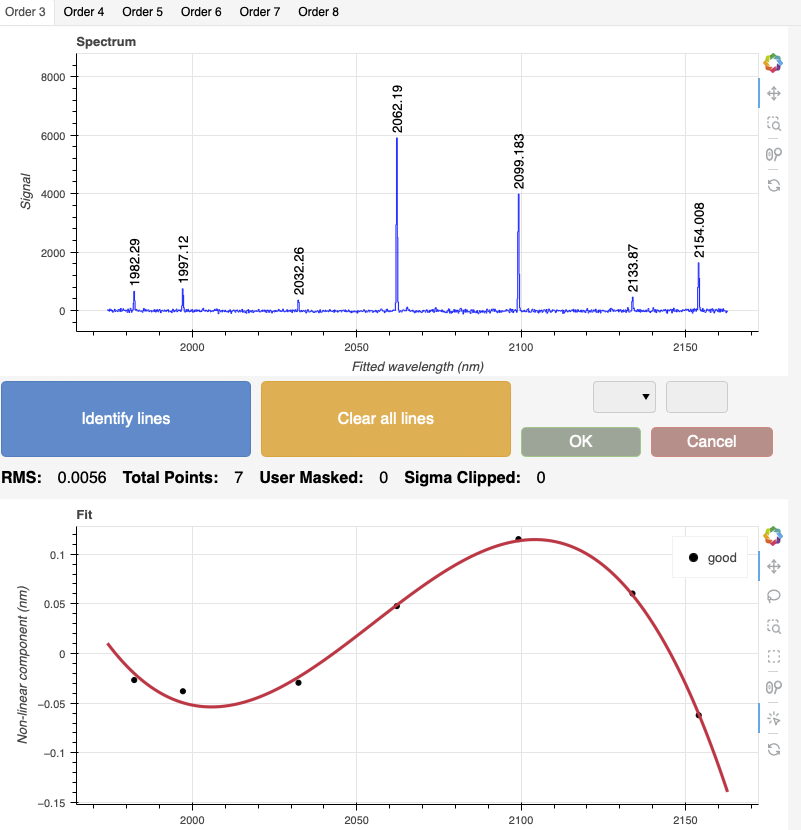
While the solutions from the arc lamp are not so bad for central wavelength
1.55 and 1.68 m, they are quite bad in general for the 1.81 m setting.
5.3.7.3. Solution from Sky Emission Lines
If the exposure times are long enough, chances are that the OH and O2 sky lines are your best bet to get a good solution in most orders at most H-band settings, especially if you do not need Order 7 and 8.
120reduce_skyarcs155 = Reduce()
121reduce_skyarcs155.files.extend(science155)
122reduce_skyarcs155.recipename = 'makeWavecalFromSkyEmission'
123reduce_skyarcs155.uparms = dict([
124 ('interactive', True),
125 ]) | nopinhole
126reduce_skyarcs155.runr()
127
128reduce_skyarcs168 = Reduce()
129reduce_skyarcs168.files.extend(science168)
130reduce_skyarcs168.recipename = 'makeWavecalFromSkyEmission'
131reduce_skyarcs168.uparms = dict([
132 ('interactive', True),
133 ]) | nopinhole
134reduce_skyarcs168.runr()
135
136reduce_skyarcs181 = Reduce()
137reduce_skyarcs181.files.extend(science181)
138reduce_skyarcs181.recipename = 'makeWavecalFromSkyEmission'
139reduce_skyarcs181.uparms = dict([
140 ('interactive', True),
141 ]) | nopinhole
142reduce_skyarcs181.runr()
For the 1.55 m setting, beware that the automatic solution for Order 7 is
completely wrong. Delete all the lines and identify them manually. Remember
to set the fit order to 3 once you have identified a few lines. Order 8 has
no solution since there are no lines. It will use an approximate linear solution
to complete. We will not be using it anyway in this case since the arc solution
for Order 8 is reasonable.
For the 1.68 m and 1.81 m settings, the solutions are generally good
except for Order 8 where the lines needs to be added manually.
5.3.7.4. Verifying the Solutions with fitTelluric
We will verify the solutions we calculated above. We have:
Arc at 1.55 |
N20191013S0034_arc.fits |
Arc at 1.68 |
N20191013S0052_arc.fits |
Arc at 1.81 |
N20191013S0070_arc.fits |
Sky lines at 1.55 |
N20191013S0006_arc.fits |
Sky lines at 1.68 |
N20191013S0010_arc.fits |
Sky lines at 1.81 |
N20191013S0014_arc.fits |
We need to run fitTelluric with each one and assess the quality of the
model for each order. We use the ucals atrribute to override the
automatic “proccessed arc” selection.
We need to use information about the star like the temperature and
the magnitude. See the section about the modeling of the telluric
below for more details. For now, create a dictionary named hip94510
with this content
143hip94510 = dict([('fitTelluric:bbtemp', 9700),
144 ('fitTelluric:magnitude', 'K=6.754')
145 ])
5.3.7.4.1. For 1.55 m
You can “Abort” fitTelluric when you are done with the inspection.
146reduce_tel155 = Reduce()
147reduce_tel155.files.extend(tellurics155)
148reduce_tel155.recipename = 'reduceTelluric'
149reduce_tel155.uparms = dict([
150 ('fitTelluric:interactive', True),
151 ]) | hip94510 | nopinhole
152reduce_tel155.ucals = dict([('processed_arc', 'N20191013S0034_arc.fits')])
153reduce_tel155.runr()
You will see that the “ringing” in the deep telluric features is well fit. Order 3 to 5, and Order 8 give a good result. In Order 6 and 7, the wavelength scale is clearly offset and the model is wrong.
154reduce_tel155 = Reduce()
155reduce_tel155.files.extend(tellurics155)
156reduce_tel155.recipename = 'reduceTelluric'
157reduce_tel155.uparms = dict([
158 ('fitTelluric:interactive', True),
159 ]) | hip94510 | nopinhole
160reduce_tel155.ucals = dict([('processed_arc', 'N20191013S0006_arc.fits')])
161reduce_tel155.runr()
The ringing is not as well fit, if at all when using the solution from the sky lines. However, the fits for Order 6 and 7 are good.
CONCLUSION
For 1.55 |
Here are examples of what to look for. First for Order 3, we can see that the model follows the ringing quite well with the arc solution and not well at all with the sky solution, even after adjust the LSF scaling factor to match what is used for the arc solution (1.06).
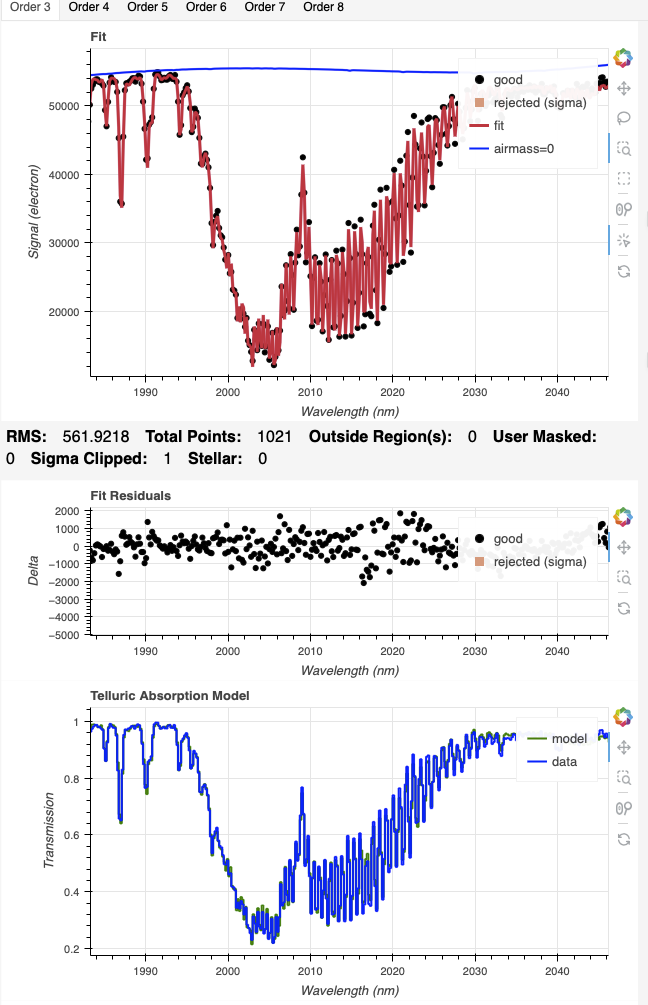
|
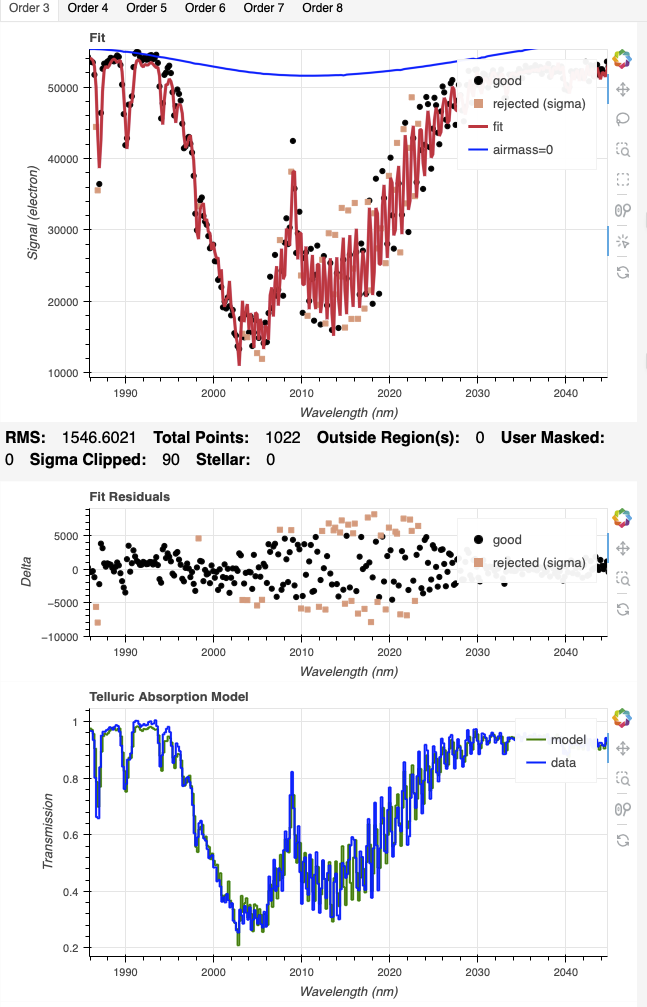
|
The second example is for Order 7, where the sky solution on the right is, while not perfect, clearly better.
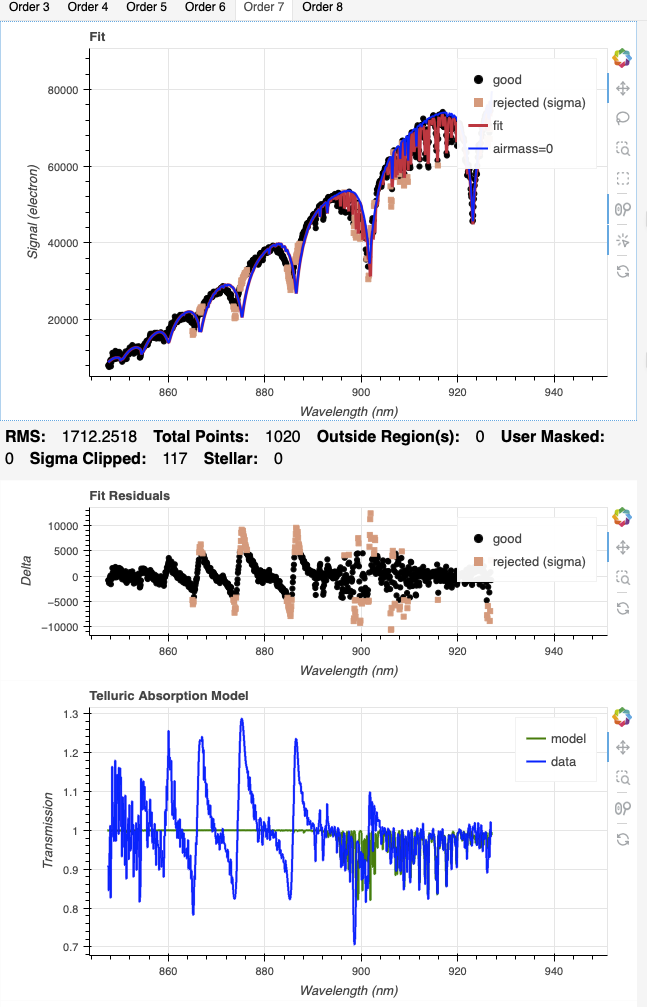
|
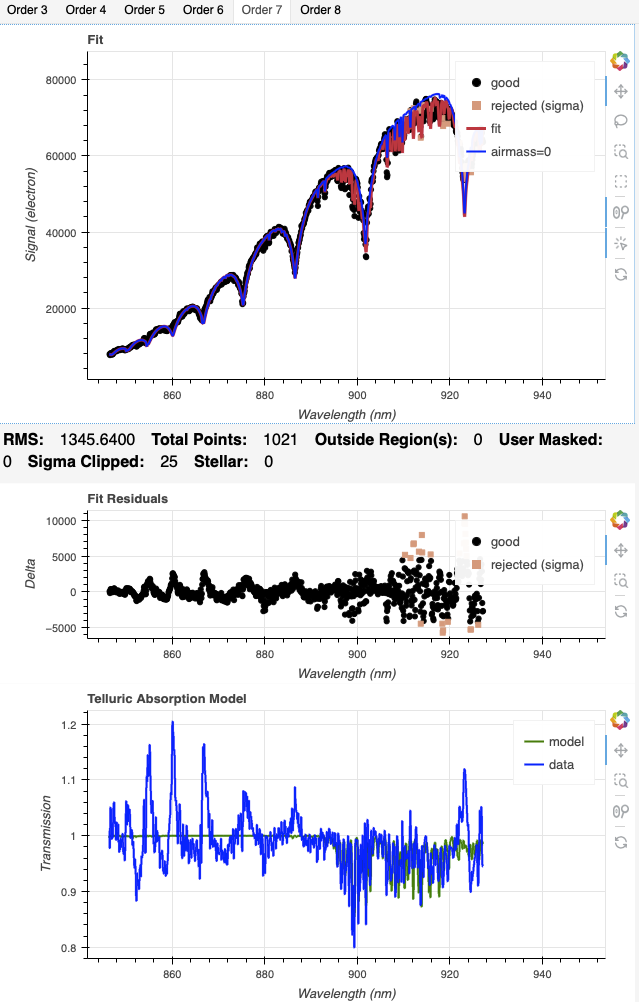
|
5.3.7.4.2. For 1.68 m
162reduce_tel168 = Reduce()
163reduce_tel168.files.extend(tellurics168)
164reduce_tel168.recipename = 'reduceTelluric'
165reduce_tel168.uparms = dict([
166 ('fitTelluric:interactive', True),
167 ]) | hip94510 | nopinhole
168reduce_tel168.ucals = dict([('processed_arc', 'N20191013S0052_arc.fits')])
169reduce_tel168.runr()
The solutions from arc are reasonable for all orders. However, we will see that the sky lines are doing better for Orders 3-7.
170reduce_tel168 = Reduce()
171reduce_tel168.files.extend(tellurics168)
172reduce_tel168.recipename = 'reduceTelluric'
173reduce_tel168.uparms = dict([
174 ('fitTelluric:interactive', True),
175 ]) | hip94510 | nopinhole
176reduce_tel168.ucals = dict([('processed_arc', 'N20191013S0010_arc.fits')])
177reduce_tel168.runr()
From the sky lines, Order 8 is not usable. But overall, the fit for the Orders are better than from the arc lamp solution.
CONCLUSION
For 1.68 |
While the differences can be obvious like for Order 8, some might be a little more subtle. For example, here we compare Order 3. The model calculated with the arc solution, on the left, is more noisy than the one with the sky solution on the right.
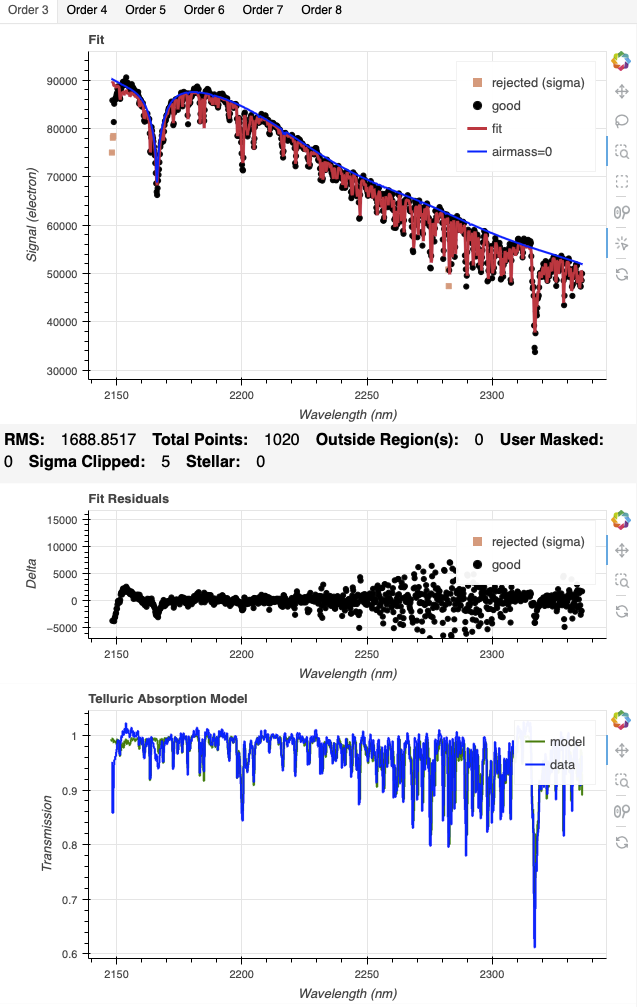
|
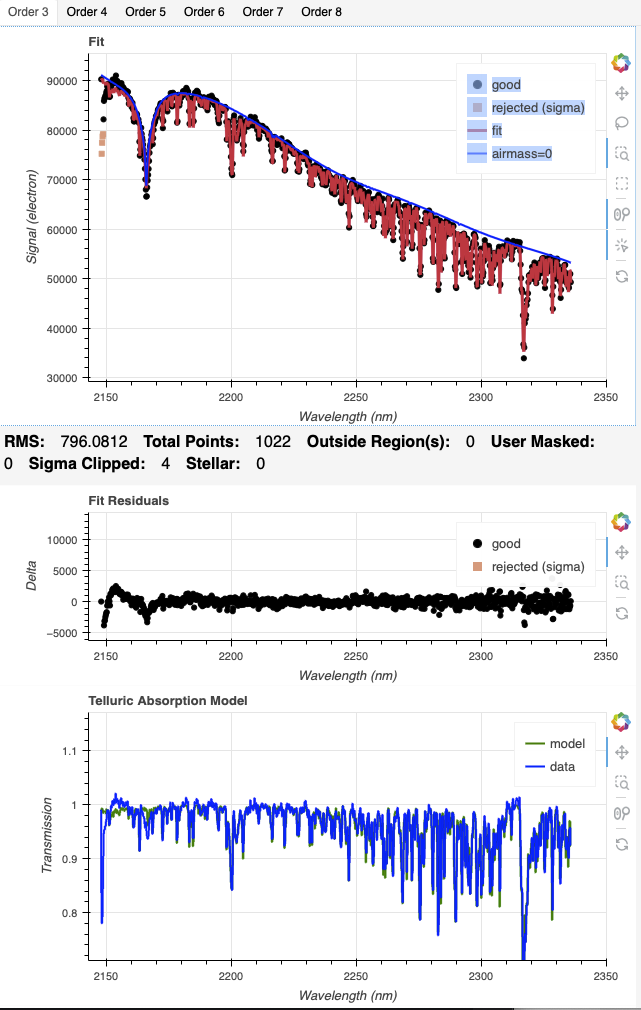
|
5.3.7.4.3. For 1.81 m
178reduce_tel181 = Reduce()
179reduce_tel181.files.extend(tellurics181)
180reduce_tel181.recipename = 'reduceTelluric'
181reduce_tel181.uparms = dict([
182 ('fitTelluric:interactive', True),
183 ]) | hip94510 | nopinhole
184reduce_tel181.ucals = dict([('processed_arc', 'N20191013S0070_arc.fits')])
185reduce_tel181.runr()
For Order 4 and 7, the model from the arc solution is clearly erroneous. Order 8 is not great but it is usable and will have to do since Order 8 from the sky lines is clearly wrong at the blue end.
186reduce_tel181 = Reduce()
187reduce_tel181.files.extend(tellurics181)
188reduce_tel181.recipename = 'reduceTelluric'
189reduce_tel181.uparms = dict([
190 ('fitTelluric:interactive', True),
191 ]) | hip94510 | nopinhole
192reduce_tel181.ucals = dict([('processed_arc', 'N20191013S0014_arc.fits')])
193reduce_tel181.runr()
With the sky line solution, it is Order 8 that is bad. The other Orders are good. The telluric fit for Order 3 is good, it is the continuum that is a bit off. We will deal with that later when we calculate the model using our final wavelength solutions.
CONCLUSION
For 1.81 |
Here is what is seen for Order 8 for the models using the arc solution (left) and the sky solution (right).
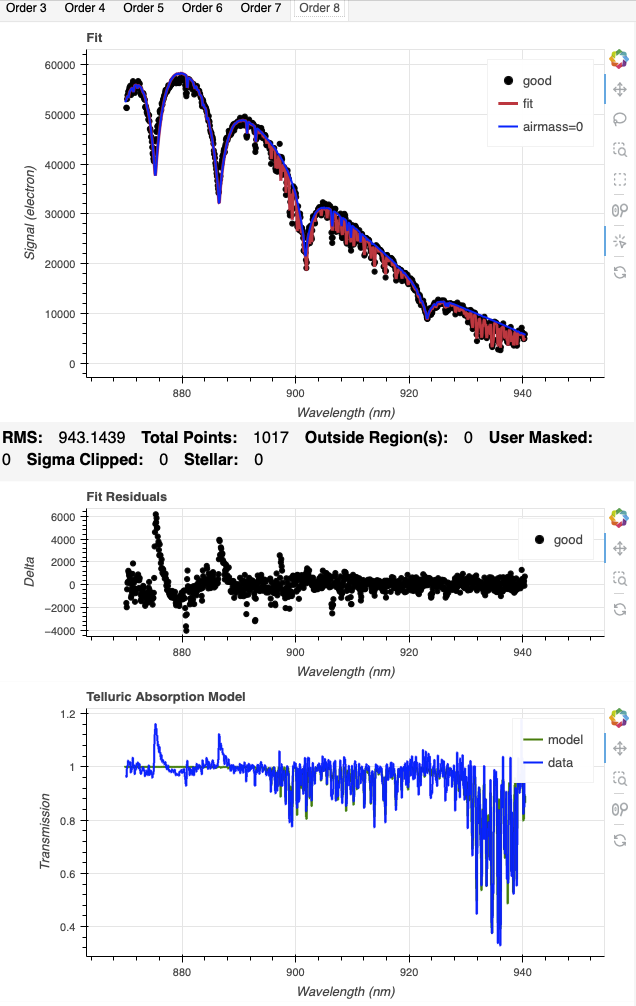
|
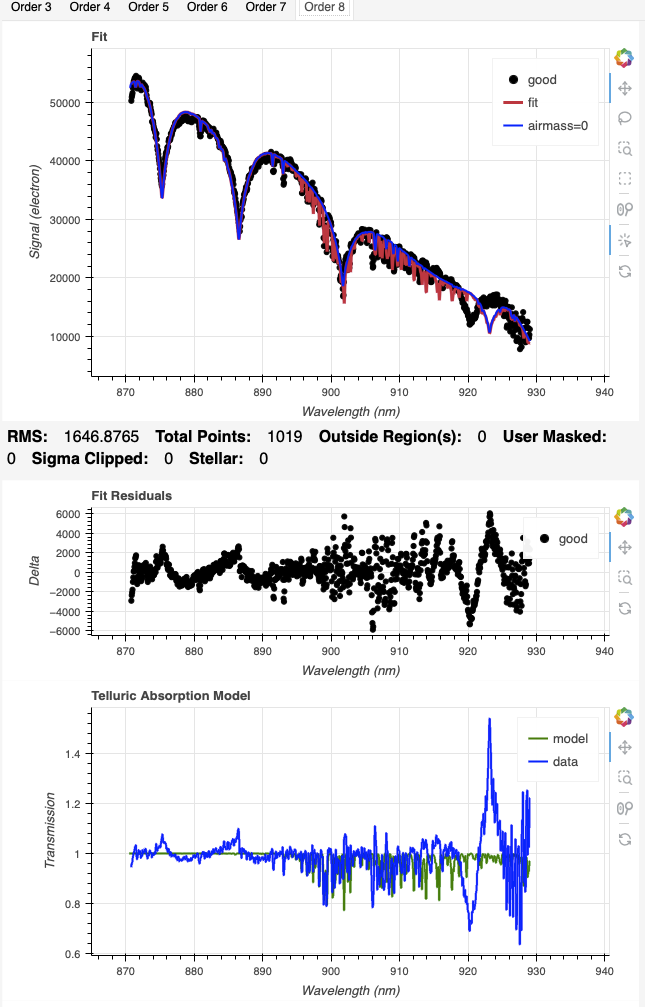
|
5.3.7.5. Combining orders
Since the solutions from the emission sky lines are often the best, we will use those solutions as our primary processed “arcs” and replace solutions in them. We can combine from two “processed arcs” at a time.
In this case, the best combinations are:
Central |
From sky lines solution |
From arc lamp solution |
1.55 |
Orders 6 and 7 |
3 to 5, and 8 |
1.68 |
Orders 3 to 7 |
8 |
1.81 |
Orders 3 to 7 |
8 |
The primitive used by the recipe to combineSlices is generic, which means
that it knows about extensions, not about “Orders”. The Orders 3 to 8 are stored in
extensions 1 to 6, respectively. This is the index scale we have to use.
It is not the most elegant solution, but for now, it works.
Combine 1.55 m:
194reduce_comb = Reduce()
195reduce_comb.files.extend(['N20191013S0006_arc.fits', 'N20191013S0034_arc.fits'])
196reduce_comb.recipename = 'combineWavelengthSolutions'
197reduce_comb.uparms = dict([('ids', '1,2,3,6')])
198reduce_comb.runr()
199
200reduce_store = Reduce()
201reduce_store.files.extend(['N20191013S0006_combinedArc.fits'])
202reduce_store.recipename = 'storeProcessedArc'
203reduce_store.uparms = dict([('suffix', '_arc155')])
204reduce_store.runr()
Combine 1.68 m:
205reduce_comb = Reduce()
206reduce_comb.files.extend(['N20191013S0010_arc.fits', 'N20191013S0052_arc.fits'])
207reduce_comb.recipename = 'combineWavelengthSolutions'
208reduce_comb.uparms = dict([('ids', '6')])
209reduce_comb.runr()
210
211reduce_store = Reduce()
212reduce_store.files.extend(['N20191013S0010_combinedArc.fits'])
213reduce_store.recipename = 'storeProcessedArc'
214reduce_store.uparms = dict([('suffix', '_arc168')])
215reduce_store.runr()
Combine 1.81 m:
216reduce_comb = Reduce()
217reduce_comb.files.extend(['N20191013S0014_arc.fits', 'N20191013S0070_arc.fits'])
218reduce_comb.recipename = 'combineWavelengthSolutions'
219reduce_comb.uparms = dict([('ids', '6')])
220reduce_comb.runr()
221
222reduce_store = Reduce()
223reduce_store.files.extend(['N20191013S0014_combinedArc.fits'])
224reduce_store.recipename = 'storeProcessedArc'
225reduce_store.uparms = dict([('suffix', '_arc181')])
226reduce_store.runr()
5.3.7.6. Cleaning up the Calibration Database
Finally, we need to clean up the calibration database to make sure only the final wavelength solutions are found in the database.
227for filedata in caldb.list_files():
228 if '_combinedArc.fits' in filedata.name or '_arc.fits' in filedata.name:
229 caldb.remove_cal(filedata.name)
A caldb list | grep arc call from the command line should show only
the 3 final wavelength solutions.
5.3.8. Telluric Standard
The telluric standard observed before the science observation is “hip 94510”. The spectral type of the star is A0V.
To properly calculate and fit a telluric model to the star, we need to know
its effective temperature. To properly scale the sensitivity function (to
use the star as a spectrophotometric standard), we need to know the star’s
magnitude. Those are inputs to the fitTelluric primitive.
The default effective temperature of 9650 K is typical of an A0V star, which is the most common spectral type used as a telluric standard. Different sources give values between 9500 K and 9750 K and, for example, Eric Mamajek’s list “A Modern Mean Dwarf Stellar Color and Effective Temperature Sequence” (https://www.pas.rochester.edu/~emamajek/EEM_dwarf_UBVIJHK_colors_Teff.txt) quotes the effective temperature of an A0V star as 9700 K. The precise value has only a small effect on the derived sensitivity and even less effect on the telluric correction, so the temperature from any reliable source can be used. Using Simbad, we find that the star has a magnitude of H=6.792.
Instead of typing the values on the command line, we will use a dictionary
named hip94510 to store them. This will be passed to Reduce.
230hip94510 = dict([('fitTelluric:bbtemp', 9700),
231 ('fitTelluric:magnitude', 'K=6.754')
232 ])
Note that the data are recognized by Astrodata as normal GNIRS cross-dispersed
science spectra. To calculate the telluric correction, we need to specify the
telluric recipe (reduceTelluric), otherwise the default science
reduction will be run.
The telluric fitting primitive can be run in interactive mode.
233reduce_tel155 = Reduce()
234reduce_tel155.files.extend(tellurics155)
235reduce_tel155.recipename = 'reduceTelluric'
236reduce_tel155.uparms = dict([
237 ('fitTelluric:interactive', True),
238 ]) | hip94510 | nopinhole
239reduce_tel155.runr()
240
241reduce_tel168 = Reduce()
242reduce_tel168.files.extend(tellurics168)
243reduce_tel168.recipename = 'reduceTelluric'
244reduce_tel168.uparms = dict([
245 ('fitTelluric:interactive', True),
246 ]) | hip94510 | nopinhole
247reduce_tel168.runr()
248
249reduce_tel181 = Reduce()
250reduce_tel181.files.extend(tellurics181)
251reduce_tel181.recipename = 'reduceTelluric'
252reduce_tel181.uparms = dict([
253 ('fitTelluric:interactive', True),
254 ]) | hip94510 | nopinhole
255reduce_tel181.runr()
The spline order defaults to 6 and that is usually a good value. You can experiment with it if you want to see how it affects the fit.
The big drop in signal in blue end of Order 3 of central wavelength 1.81 m
is not fit well at all with the default spline order. It is an extreme case
that seems to be best modeled with a spline order of 30. Play with it to see
the effect on each plot of the interactive tool.
5.3.9. Science Observations
The science target is a recurrent nova. The sequence is a set of ABBA dither pattern at three central wavelengths. DRAGONS will flatfield, wavelength calibrate, subtract the sky, stack the aligned spectra, extract the source, and finally remove telluric features and flux calibrate.
Note
In this observation, there is only one real source to extract. If there were multiple sources in the slit, regardless of whether they are of interest to the program or not, DRAGONS will locate them, trace them, and extract them automatically. Each extracted spectrum is stored in an individual extension in the output multi-extension FITS file.
This is what one raw image looks like.

What you see are from left to right the cross-dispersed orders, from Order 3 to Order 8. The short horizontal features are sky lines. The “vertical lines” are the dispersed science target in each order. In the raw data, the red end is at the bottom and blue at the top. This will be reversed when the data is resampled and the distortion corrected and wavelength calibration are applied.
With all the calibrations in the local calibration manager, for a Quicklook
Quality output, one only needs to call Reduce on the science frames to get
an extracted spectrum.
256reduce_sci155 = Reduce()
257reduce_sci155.files.extend(science155)
258reduce_sci155.uparms = nopinhole
259reduce_sci155.runr()
For a Science Quality output, it is recommended to run the reduction in interactive mode, in particular to adjust the wavelength shift often needed for the telluric correction.
To run the reduction with all the interactive tools activated, set the
interactive parameter to True. In this case, the need for
interactivity lies mostly in the telluric correction since an offset in
wavelength needs to be applied. This is not always needed but it’s safer to
verify anyway. To target that step, one would use
('telluricCorrect:interactive', True) instead of the non-specific call that
activates all the interactive steps.
260reduce_sci155 = Reduce()
261reduce_sci155.files.extend(science155)
262reduce_sci155.uparms = dict([('interactive', True)]) | nopinhole
263reduce_sci155.runr()
264
265reduce_sci168 = Reduce()
266reduce_sci168.files.extend(science168)
267reduce_sci168.uparms = dict([('interactive', True)]) | nopinhole
268reduce_sci168.runr()
269
270reduce_sci181 = Reduce()
271reduce_sci181.files.extend(science181)
272reduce_sci181.uparms = dict([('interactive', True)]) | nopinhole
273reduce_sci181.runr()
When you get to the telluricCorrect step, you can experiment with the
shift between the telluric standard and the target. Both need to be well
aligned in wavelength to optimize the correction. We find that the following
offsets are required: -0.7 for 1.55 m, -0.1 for 1.68 m, and -0.11 for
1.81 m.
(Depending on your interactive adjustments during wavelength calibrations and the calculation of the telluric model, those offsets might be different for you.)

A section of 2D spectrum before extraction is shown on the right, with blue wavelengths at the bottom and the red-end at the top. Note that each order has been rectified and is being stored in separate extensions in the MEF file. Here they are displayed together, side by side.
Each order is extracted separately and stored in separate extensions in the
MEF file. The 1D extracted spectrum before telluric correction or flux
calibration, obtained by adding the option
('extractSpectra:write_outputs', True) to the Reduce instance.
You can
plot all the orders on a common plot with dgsplot.
from gempy.adlibrary import plotting
ad = astrodata.open('N20191013S0006_extracted.fits')
plotting.dgsplot_matplotlib(ad, 1, kwargs={'linewidth':0.5})
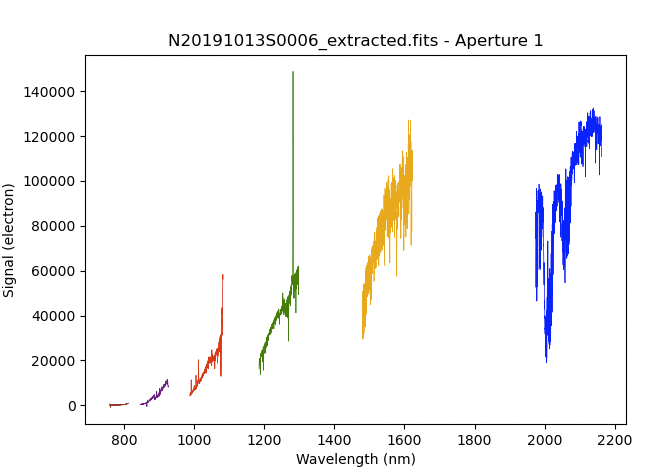
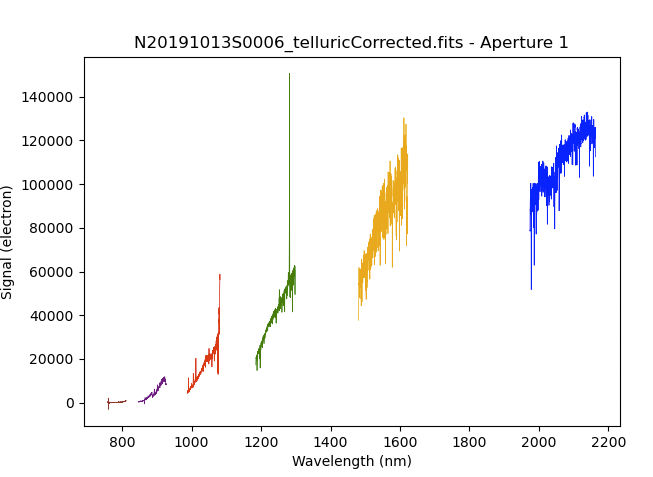
The 1D extracted spectrum after telluric correction but before flux
calibration, obtained with ('telluricCorrect:write_outputs', True), looks
like this.
from gempy.adlibrary import plotting
ad = astrodata.open('N20191013S0006_telluricCorrected.fits')
plotting.dgsplot_matplotlib(ad, 1, kwargs={'linewidth':0.5})
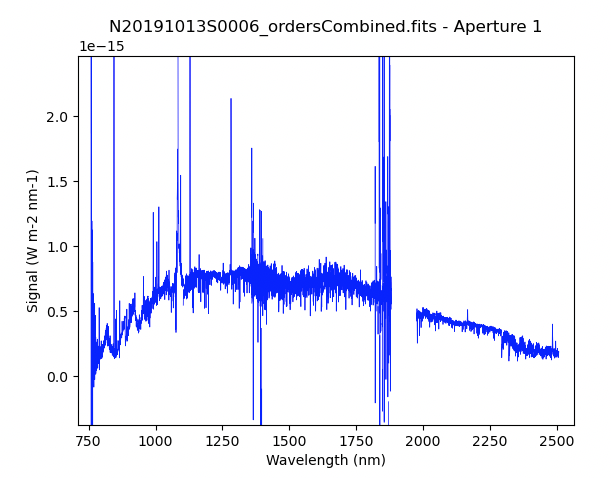
And the final spectrum for one central wavelength setting, corrected for telluric features and flux calibrated.
from gempy.adlibrary import plotting
ad = astrodata.open('N20191013S0006_1D.fits')
plotting.dgsplot_matplotlib(ad, 1, kwargs={'linewidth':0.5})
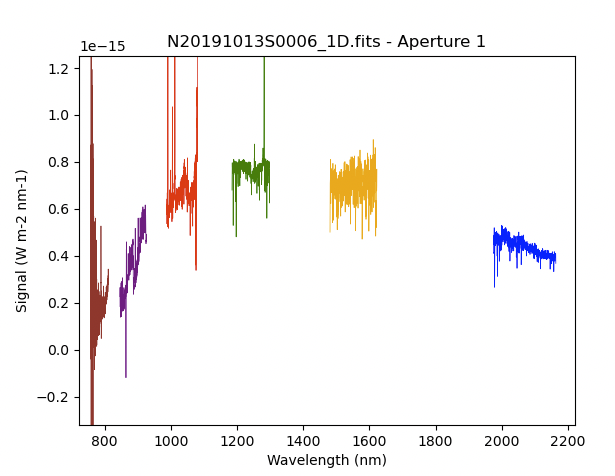
In the final spectrum, the orders remain separated. Here they are simply plotted one after the other on a common plot.
The plots above are for one central wavelength setting. We probably want to
scale and stitch all the orders from all 3 final spectra together to get one
continuous spectrum. We use the primitive combineOrders to do that.
274reduce_combine = Reduce()
275reduce_combine.recipename = 'combineOrders'
276reduce_combine.files.extend([reduce_sci155.output_filenames[0],
277 reduce_sci168.output_filenames[0],
278 reduce_sci181.output_filenames[0]])
279reduce_combine.uparms = dict([('scale', True)])
280reduce_combine.runr()
from gempy.adlibrary import plotting
ad = astrodata.open('N20191013S0006_ordersCombined.fits')
plotting.dgsplot_matplotlib(ad, 1, kwargs={'linewidth':0.5})